Methodology of Recurrent Neural Networks
The main idea of RNN is to use a hidden variable to store history information and pass that information recursively to the down stream of inputs, as shown in the figure below (a):
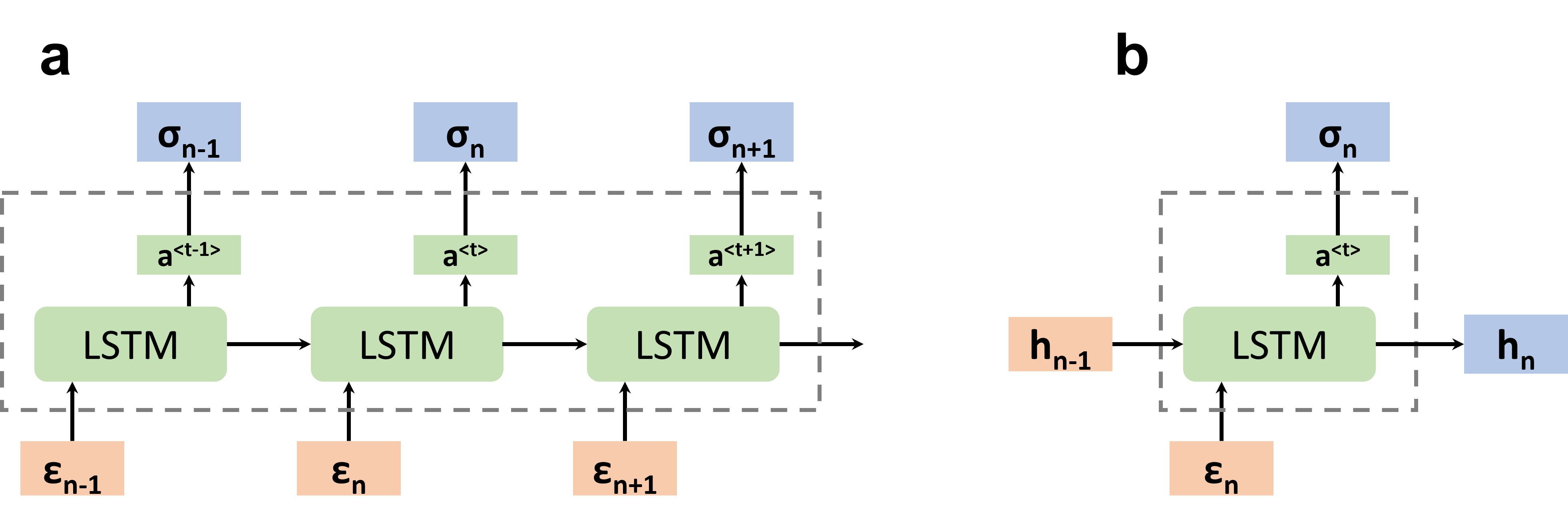
LSTM architectures in many-to-many (a) and one-to-one form (b).
where h is the hidden variable decoupled in the right figure.
One notices that by using the hidden state vector h, the RNN is able to transmit information from earlier states to later states. The intrinsic philosophy exactly resembles the methodology of constitutive modeling of history-dependent materials. This built-in similarity makes the RNNs naturally fit to learn the viscoelastic law. Here RNN is adopted to learn the constitutive law of infinitesimal strain viscoelasticity, with the details of which shown in the CM-002 tutorial.
Performance
The stress-strain pairs sampled from classical VE constitutive law were used as training data. After the training, the model can well predict the stress from unseen strain inputs. However, ML is essentially an interpolation method, its extrapolation ability is limited depending on how large the prediction data is different from those used for training, as indicated by a small-scale and large-scale extrapolation tests as shown below.
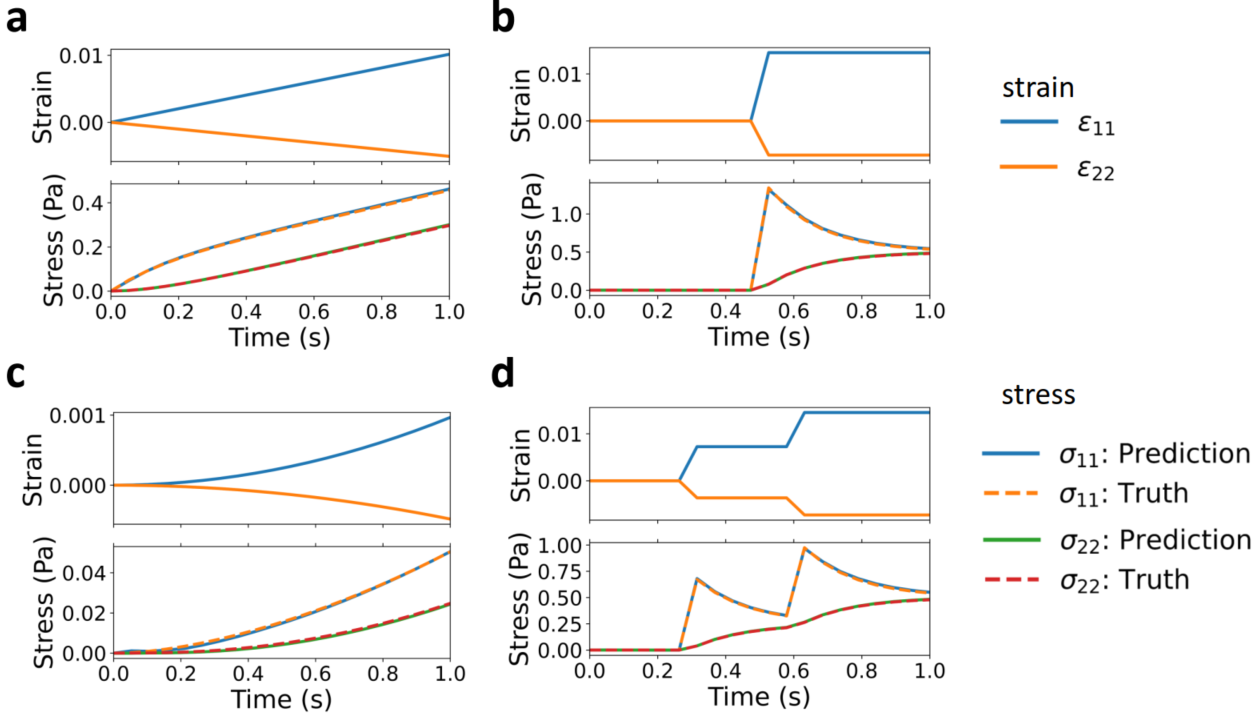
RNN-VE model prediction on small-scale extrapolation.
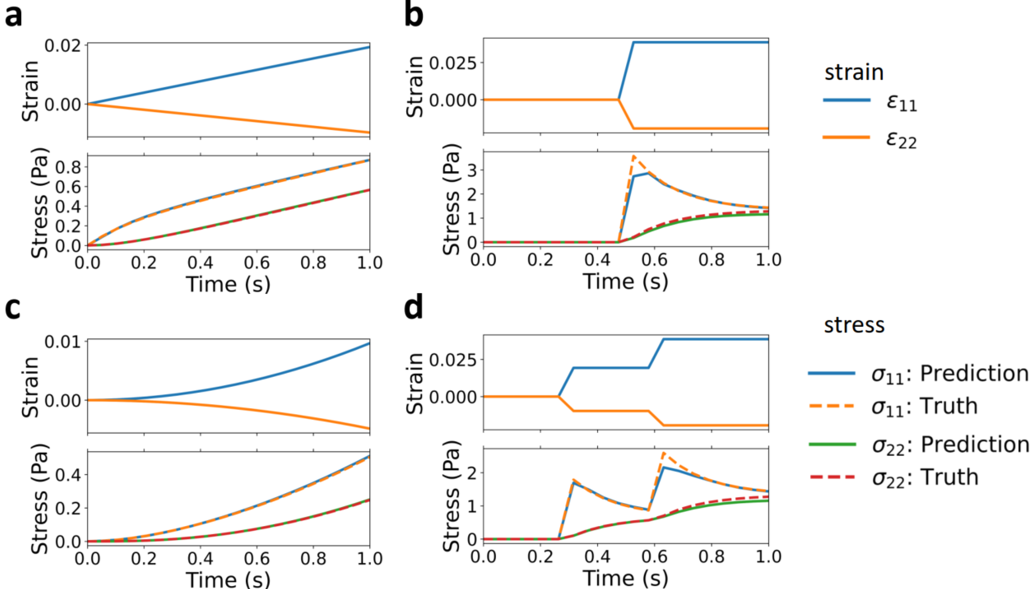
RNN-VE model prediction on large-scale extrapolation.
The code for developing the RNN-VE model can be found at the Github repo.
References
[1] Simo, Juan C., and Thomas JR Hughes. Computational inelasticity. Vol. 7. Springer Science & Business Media, 2006.
[2] Chen, Guang. “Recurrent neural networks (RNNs) learn the constitutive law of viscoelasticity.” Computational Mechanics 67.3 (2021): 1009-1019.