Molecular Generation
In materials science field, the forward problem, e.g., given materials structural information, seek the property of the material (structure-property relationship), is relatively straightforward and easy (well-established experiments, theory, and simulations). While the inverse problem (property space to material space), often presented in materials design when only materials with desired properties are needed, is more complicated. There are many generative models (GAN, etc.) that can be employed for this goal. In this post, the RNN is applied for molecular generative task.
The Problem and the Model
The objective of the RNN model is to generate a sequence, which denotes a polymer (specially its monomer unit) by the SMILES string [1]. Let a sequence be , the probability to find this sequence is:
Unfortunately, there is little known about the probability distribution function. Thus, one can only resort to a large training database. The data seen by the Model is therefore the model’s “world”.
Here is the model of RNN molecular generation:
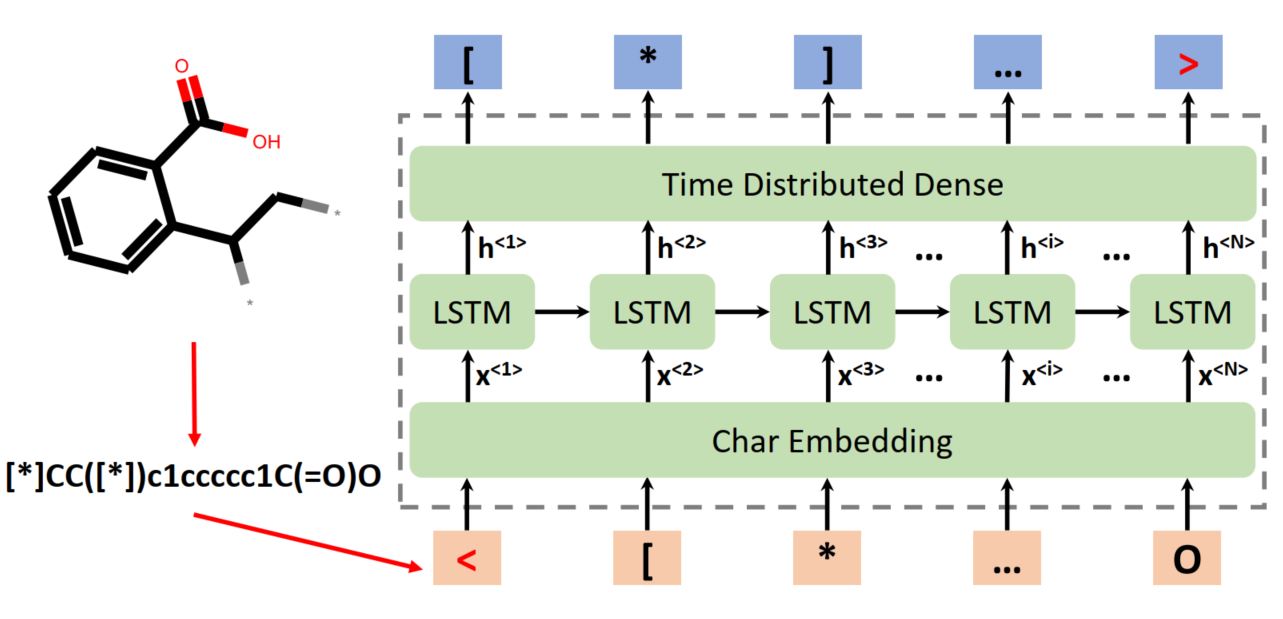
RNN molecular generation model.
For simplicity, there are three layers in the model:
- an embedding layer transforming input tokens into vectorized features
- an LSTM layer with hidden information
- a time distributed dense layer
In the preprocessing step, all inputs (SMILES strings) are tokenized into vectors using a dictionary containing all the characters in the strings. The strings are padded to match a maximum length. The training process, is essentially to find a classifier predicting a new character given previous ones.
Here using pyTorch, code snippet is demonstrated. Forward pass of the model:
def forward(self, x, hidden):
"""Forward pass: char to char level prediction model"""
# embedding layer
x1 = self.embedding(x)
# lstm layer
x1, next_hidden = self.lstm(x1, hidden)
# forward connected layer
out = self.fc(x1)
return out, next_hidden
The training step:
def fit(self, dataloader, epochs, print_freq):
"""model training function"""
loss_avg = 0.0
losses = []
for epoch in range(epochs):
# loop over batches
for step, (x_padded, y_padded, x_lens, y_lens) in enumerate(dataloader):
# the input and output
inp = x_padded.to(self.device)
target = y_padded.to(self.device)
# hidden variables
hidden = self.init_hidden(x_padded.shape[0])
pred, hidden = self(inp, x_lens, hidden) # pred in [batch_size, seq_len, nb_tags]
# sum up loss
batch_loss = 0.0
for i in range(pred.size(0)):
ce_loss = F.cross_entropy(pred[i], target[i], ignore_index=49)
batch_loss += ce_loss
loss_avg += batch_loss.item() # total loss of all samples
# back-propagation
self.optimizer.zero_grad()
batch_loss.backward()
self.optimizer.step()
losses.append(loss_avg/len(dataX)) # average loss of a sample
if epoch % print_freq == 0:
print("Epoch [{}/{}], Loss {:.4e}".format(epoch+1, epochs, loss_avg/len(dataX)))
loss_avg = 0.0
return losses
After the training step, the generation step is:
def generation(self, tokens, max_seq_len=150):
"""generation step on CPU"""
# start with '<'
start = tokens[0]
newSMILES = ''.join(start)
# prepare the inp for generation
inp = tc.tensor(self.char2int[start]).view(1,-1)
# hidden variable
hidden = self.init_hidden(1, device='cpu')
for timestep in range(max_seq_len):
# forward pass
x1 = self.embedding(inp)
x1, hidden = self.lstm(x1, hidden)
output = self.fc(x1)
# use softmax to get the most probable idx
max_prob = tc.softmax(output, dim=2).view(-1)
top_idx = tc.multinomial(max_prob, 1)[0].cpu().numpy() # has to be set for random generation
# get the most chars
pred_char = self.int2char[int(top_idx)]
# update SMILES
newSMILES += pred_char
# update inp
inp = tc.tensor(self.char2int[pred_char]).view(1,-1)
# determine the length
if pred_char == tokens[1]: # end token '>'
break
return newSMILES
Note that this example is just about molecular generation, no any materials property is involved in training.
References
[1] SMILES: Simplified molecular-input line-entry system [Wiki].